Python分布式任务调度框架Celery的原理梳理
一、介绍
Celery是一个开源的分布式任务队列,专注于实时处理和任务调度。他基于Python编写,并广泛应用于需要处理大量并发任务的应用中。Celery提供了简单而灵活的API,允许开发者通过异步的方式执行任务,并支持任务的调度、监控和结果处理。
下面是一些常见的应用场景及其详细说明:
1. 异步任务处理
异步任务处理是 Celery 最常见的用途之一,适用于那些不需要立即返回结果的任务。这些任务可以在后台处理,不会阻塞主线程的执行,从而提高应用程序的响应速度和用户体验。
- 发送电子邮件:用户注册后发送欢迎邮件,或者在交易完成后发送确认邮件。
- 生成报告:处理大量数据,生成复杂的报表或统计分析,通常这些操作会花费较长时间。
- 图像处理:如缩放、裁剪和滤镜应用等操作,可以在后台进行,用户不必等待处理完成。
2. 定时任务
Celery 提供了定时任务调度功能,可以定期执行特定任务。此功能类似于 cron 作业,但更灵活和强大。
- 数据备份:每天定时备份数据库,确保数据安全。
- 定时统计:每天定时生成统计报告,如网站访问量统计、用户行为分析等。
- 自动更新:定期从外部数据源获取最新数据并更新本地数据库。
3. 分布式任务调度
Celery 支持分布式任务调度,通过部署多个 Workers,任务可以在多个节点上并行处理,从而实现负载均衡和高可用性。
- 大规模数据处理:例如,处理海量日志文件,进行数据清洗和分析。
- 并发处理:多个用户请求同时到来时,可以通过分布式 Workers 并发处理,提升系统性能。
- 分布式计算:在大规模计算任务中,将计算任务分配到多个计算节点,利用集群资源提升计算效率。
4. 实时数据处理
Celery 可以处理实时生成的数据流,适用于需要快速响应和处理的场景。
- 实时分析:对实时生成的用户行为数据进行分析,如实时推荐系统、实时监控和报警系统。
- 数据清洗:实时处理和清洗数据,如日志解析、格式转换等。
- 流处理:处理实时数据流,如金融交易数据处理、社交媒体数据分析等。
二、原理
1.模块架构
Celery的核心原理基于消息中间件,通常使用RabbitMQ、Redis来作为任务的传输和调度中心。
基本的工作流程包含如下三个部分:
- 生产者:负责发布任务到消息队列
- 消息队列:作为任务的缓冲区和调度中心,存储待执行的任务
- 消费者(CeleryWorker):监听消息队列,获取任务并执行
在网上找了一张图,展示的比较清晰。celery使用消息中间件做消息代理,将任务发布至消息队列,而分布在多个服务器上的CeleryWorker监听同一个消息队列,当有新任务时任务会是负载情况分配给空闲的节点执行,异步执行的结果可以通过远程调用RPC的方式去做一个存储。
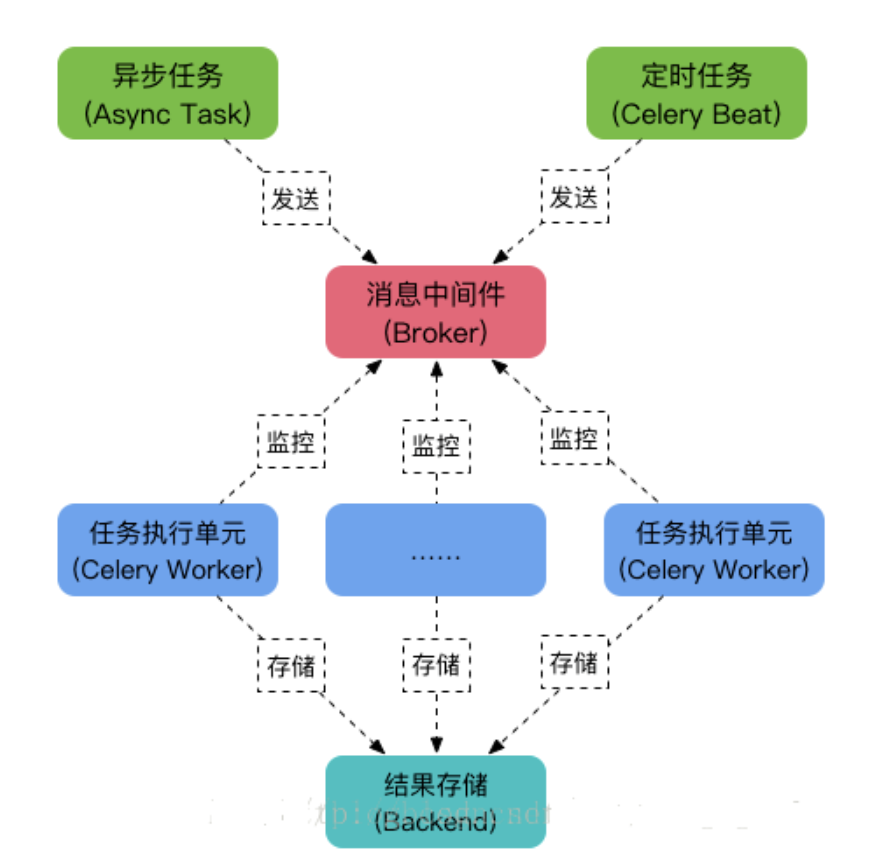
Celery 支持多种消息中间件,通过配置可以灵活选择适合项目需求的消息队列,以实现任务的异步执行和分布式调度。
2.功能和优势
Celery 在分布式任务调度中的主要功能和优势包括:
- 消息中间件的选择:支持多种消息中间件,如
RabbitMQ、Redis等,根据需求选择适合的消息队列。 - 水平扩展能力:通过添加和配置多个
Workers,实现任务的水平扩展,提高系统的处理能力和并发性能。 - 任务优先级和调度策略:支持任务的优先级设置和灵活的调度策略,根据业务需求优化任务的执行顺序和调度方式。
- 监控和管理:通过工具如
Flower,实时监控和管理任务执行状态、Worker节点状态等,便于故障排查和性能调优。
三、部分实现细节
Celery 是一个功能强大的分布式任务队列系统,它的底层实现涉及多个组件和库。以下是Celery 的一些关键底层实现细节:
1. 消息传递
Celery 使用消息队列来传递任务消息。常见的消息队列后端包括 RabbitMQ、Redis 等。Celery 通过这些消息队列来分发任务给 Workers。
1.1 消息格式
Celery 发送的消息通常是 JSON 格式的字符串,包含任务的详细信息,如任务名称、参数等。
{
"task": "my_app.tasks.add",
"id": "7e83e1c5-60db-4c8d-87d0-e9e6878d7d4a",
"args": [4, 6],
"kwargs": {},
"retries": 0,
"eta": null
}1.2 消息传递流程
- 任务发布:客户端通过
apply_async或delay方法将任务发布到消息队列。 - 消息队列:消息队列(如
RabbitMQ)接收并存储任务消息。 - Worker 消费:Worker 从消息队列中获取任务消息并执行任务。
2. Worker 实现
Worker 是 Celery 的核心组件,负责执行任务。Worker 的实现涉及以下几个方面:
2.1 任务执行
Worker 通过 pickle 或 json 等序列化方式反序列化任务消息,并调用相应的任务函数执行任务。
@app.task
def add(x, y):
return x + y2.2 并发模型
Celery 支持多种并发模型,如 prefork(多进程)、gevent、eventlet 等。默认情况下,Celery 使用 prefork 模型,通过多进程来实现并发。
celery -A my_app worker --concurrency=42.3 任务结果存储
Worker 执行完任务后,会将结果存储到结果后端(如 Redis、数据库等)。客户端可以通过任务 ID 查询任务结果。
result = add.delay(4, 6)
print(result.get()) # 输出 103. 定时任务
Celery 支持定时任务调度,通过 celery beat 进程来实现。
3.1 定时任务配置
定时任务通过配置文件或代码进行配置,指定任务的执行时间和频率。
from celery.schedules import crontab
app.conf.beat_schedule = {
'add-every-30-seconds': {
'task': 'my_app.tasks.add',
'schedule': 30.0,
'args': (16, 16)
},
}3.2 定时任务调度
celery beat 进程会根据配置定时将任务发布到消息队列,Worker 会从队列中获取并执行这些任务。
celery -A my_app beat4. 监控和管理
Celery 提供了丰富的监控和管理功能,可以通过 flower 等工具来监控任务执行情况、Worker 状态等。
4.1 Flower
flower 是一个基于 Web 的监控工具,可以实时查看任务状态、Worker 状态、任务执行历史等。
celery -A my_app flower四、在项目中的应用
在项目中,Celery 的应用可以帮助解决以下问题和优化任务处理流程:
1. 处理复杂业务逻辑
在实际项目中,业务逻辑通常比较复杂,将这些复杂的业务逻辑分解为多个小任务,并异步执行,可以提高系统的响应速度和用户体验。
- 订单处理:在电商平台中,订单处理可能涉及多步操作,如库存检查、支付确认、发货等。这些操作可以拆分为多个小任务,异步执行。
- 用户认证:在用户注册和登录过程中,可能需要进行多种验证操作,如验证码验证、邮件验证、第三方身份验证等。这些操作可以异步处理,提高系统响应速度。
2. 降低系统负载
通过异步任务处理,可以将耗时较长的操作从主线程中剥离出来,减少主线程的阻塞,优化系统资源利用。
- 文件上传和处理:用户上传文件后,可以在后台异步处理,如文件格式转换、病毒扫描等,不阻塞用户的操作。
- 数据导入:大量数据导入操作可以异步处理,避免阻塞主线程,提高系统性能。
3. 提高任务执行效率
利用 Celery 的分布式架构,可以部署多个 Workers,实现任务的并行处理和快速响应。
- 大规模计算:在需要进行大规模计算的场景下,可以将计算任务分配到多个 Workers 并行处理,提高计算效率。
- 高并发请求处理:在高并发场景下,可以通过部署多个 Workers 并行处理用户请求,提升系统的吞吐量和响应速度。
4. 增强系统可靠性
通过消息队列的持久化特性,确保任务数据不会丢失,增强系统的可靠性和稳定性。
- 任务重试机制:当任务执行失败时,Celery 可以自动重试,确保任务最终执行成功。
- 任务结果持久化:任务结果可以持久化存储,确保在系统重启或故障恢复后,任务结果不会丢失。